Petals:大型模型的协同推理和微调
arxiv.org - Petals: Collaborative Inference and Fine-tuning of Large Models
Abstract
许多 NLP 任务受益于使用通常具有超过 1000 亿个参数的大型语言模型 (LLMs)。随着 BLOOM-176B 和 OPT-175B 的发布,每个人都可以下载这种规模的预训练模型。尽管如此,使用这些模型仍然需要许多研究人员无法获得的高端硬件。在某些情况下,通过 RAM 卸载或托管 API 可以更经济地使用 LLMs。然而,这些技术具有先天的局限性:对于交互式推理来说,卸载速度太慢,而 API 对于研究来说不够灵活。在这项工作中,我们提出 Petals —— 通过加入受信任处理客户数据的多方资源来协作推理和微调大型模型的系统。我们证明,对于非常大的模型,该策略的性能显着优于卸载,在消费级 GPU 上以每秒 ≈ 1 步的速度运行 BLOOM-176B 的推理。与大多数推理 API 不同,Petals 本身还公开了所服务模型的隐藏状态,允许用户基于高效的微调方法来训练和共享自定义模型扩展。
1 Introduction
近年来,NLP 社区发现预训练语言模型可以解决许多实际任务,通过微调或简单的提示。此外,随着规模的增加,性能往往会提高。遵循这一趋势,现代语言模型通常具有数千亿个参数。几个研究小组发布了具有超过 100B 参数的预训练 LLMs ;最近,BigScience 项目发布了 BLOOM,这是一个 1760 亿个参数模型,支持 46 种自然语言和 13 种编程语言。
虽然 100B+ 参数模型的公开可用性使它们更容易访问,但由于内存和计算成本,它们对于大多数研究人员和从业者来说仍然难以使用。例如,OPT-175B 和 BLOOM-176B 需要超过 350GB 的加速器内存用于推理,并且需要更多的加速器内存用于微调。 因此,这些LLMs通常需要多个高端GPU或多节点集群才能运行。这两种选择都极其昂贵,限制了大型语言模型的潜在研究方向和应用。
最近的几项工作旨在通过将模型参数“卸载(offloading)”到速度较慢但更便宜的内存(RAM 或 SSD),然后在加速器上逐层运行它们来实现民主化LLMs。 此方法允许通过为每个前向传递即时从 RAM 加载参数来使用单个低端加速器运行 LLMs。卸载可以高效地并行处理许多令牌,但它本质上具有很高的延迟:例如,使用 BLOOM-176B 生成一个令牌对于最快的 RAM 卸载设置至少需要 5.5 秒,而对于最快的 SSD 卸载则需要 22 秒。此外,许多计算机没有足够的 RAM 来卸载 175B 参数。
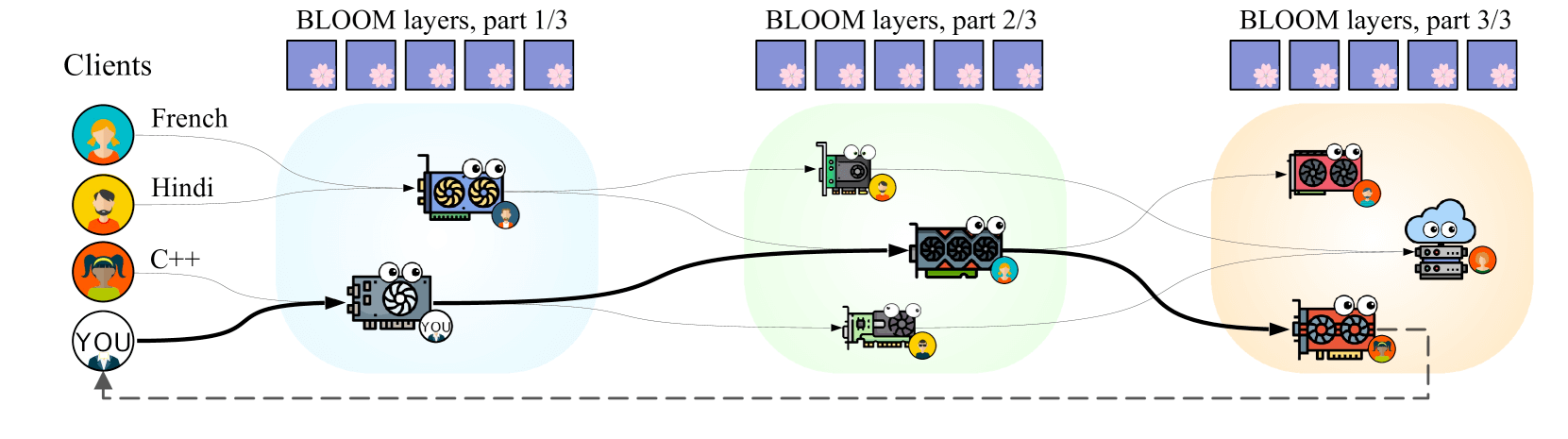
图 1:花瓣概述。一些参与者(客户)希望使用预训练的语言模型来解决涉及处理自然语言(例如法语、印地语)或编程语言(例如 C++)文本的各种任务。他们在其他参与者(服务器)的帮助下完成此任务,这些参与者在其 GPU 上保存模型层的各种子集。每个客户端选择一系列服务器,以便在最短的时间内执行推理或微调步骤。
另一种使 LLMs 更易于访问的方法是通过公共推理 API,其中一方托管模型并让其他人通过互联网 查询该模型。由于大部分工程工作是由 API 所有者完成的,因此这是一个相对用户友好的选项。然而,API 对于研究用途来说通常不够灵活:无法更改模型控制流或访问内部状态。最重要的是,当前的 API 定价可能会使一些研究项目过于昂贵。
在这项工作中,我们探索了一种替代策略,其灵感来自 Ryabinin 和 Gusev(2020)从头开始的神经网络众包分布式训练。我们推出了 Petals,这是一个允许多个用户通过互联网协作并对大型语言模型进行推理和微调的平台。每个参与者都运行一个服务器、一个客户端或两者都运行。服务器在其本地设备上保存模型层的子集(通常是 Transformer 块)并处理来自客户端的请求。客户端可以形成一系列管道并行的连续服务器来运行整个模型的推理(第 2.1 节)。除了推理之外,参与者还可以通过参数高效的训练方法对模型进行微调。 或通过训练整个层(第 2.2 节)。经过训练后,子模块可以在模型中心共享(第 2.3 节),其他人可以使用它们进行推理或进一步训练。
在第 3 节中,我们证明现有的 100B+ 模型可以在多种优化的帮助下在此设置中高效运行:动态量化、优先考虑低延迟连接以及服务器之间的负载平衡。最后,在第 4 节中,我们讨论了参与系统的激励措施、安全性和隐私性,以及模型如何随着时间的推移进行更新。
2 Design and use cases
大型语言模型的实际使用可以大致分为两个主要场景:推理 和 对下游任务的参数高效适应。在本节中,我们概述了 Petals 的设计,展示了它如何处理这两种场景,并且还允许在系统用户之间轻松共享经过训练的适配器。
2.1 Inference of billion-scale models
生成令牌时,客户端在本地存储模型的令牌嵌入(通常只占参数总数的一小部分,可以容纳在大多数现代笔记本电脑、服务器和工作站的 RAM 中),并依赖服务器来运行 Transformer 块。每个服务器拥有多个连续的块,其数量取决于服务器的可用 GPU 内存。在每次推理会话之前,客户端都会找到一个服务器链,这些服务器共同保存所有模型层。
一旦链形成,客户端使用本地嵌入层查找前缀标记的嵌入向量,然后将这些向量发送到服务器并接收新的表示。一旦客户端获得最终块的输出,它就会计算下一个令牌概率并重复此过程。
当会话处于活动状态时,服务器会存储过去客户端输入的注意键和值,并将它们用于后续的推理步骤。客户端还将过去的输入存储到每台服务器,以便如果任何服务器发生故障或离线,另一台服务器可以快速取代它。第 3.2 节详细介绍了查找服务器和从故障中恢复的过程。
Client-side API. 客户端 API
要使用 Petals 生成令牌,首先创建一个推理会话。推理会话迭代地将输入作为 PyTorch 张量,在所有 Transformer 块中运行它们,并返回最终表示作为 PyTorch 张量。在底层,会话形成服务器链、保存缓存并以对用户透明的方式从服务器故障中恢复。图 2 显示了使用推理会话的示例。
# Initialize distributed BLOOM model
model = DistributedBloomForCausalLM \
.from_pretrained("bigscience/bloom-petals")
input_ids = tokenizer(prefix_text)
with model.inference_session() as session:
# Session maintains a set of servers that
# store attention KV from previous steps
for _ in range(sequence_length):
# Compute the word embeddings locally
hid = model.word_embeddings(input_ids)
# Run distributed Transformer blocks,
# store attention KV for future steps
hid = session.step(hid)
# Sample the next token locally
probs = model.lm_head(hid)
input_ids = sample_next_token(probs)
System requirements. 系统要求
对于 BLOOM-176B 推理,客户端至少需要 12 GB RAM,其中大部分用于存储 3.6B 嵌入参数。 我们 建议至少 25 Mbit/s 的双向带宽,以避免网络传输出现瓶颈。 简单的贪婪推理可以使用任何运行 PyTorch 的 CPU,但更高级的算法(例如波束搜索)可能需要 GPU。
反过来,服务器需要至少 16 GB CPU RAM、100 Mbit/s 带宽以及图灵一代或更新版本的 GPU(具有至少 8 GB 内存)。
Graphical user interface. 图形用户界面
我们还提供了一个示例应用程序,让用户可以在类似信使的用户界面中与模型聊天。该界面分为两个主要块:前端和后端应用程序。我们使用 Hugging Face Spaces 作为后端应用程序,为每个请求在 CPU 上运行贪婪推理。它可以通过 Python 的 requests 库轻松使用;因此,任何人都可以使用此设置作为后端并以任何格式构建自己的前端应用程序。为了更好地了解如何使用此后端,我们提供了一个使用 Hugging Face Spaces 和 Streamlit API 的示例前端应用程序。在此浏览器应用程序中(如图 3 所示),用户可以通过输入文本提示并接收生成的输出来与模型进行通信。
图 3:用于 Petals 推理的用户界面原型。
2.2 Training for downstream tasks 下游任务的训练
虽然 LLMs 通过简单的提示工程在许多问题上实现了高质量,他们经常需要培训才能达到最佳结果。传统上,这是通过微调下游任务的所有模型参数来完成的。然而,对于非常大的模型,由于硬件要求,这种策略变得不切实际。例如,使用 Adam 微调 BLOOM-176B 将需要近 3 TB 的 GPU 内存来存储模型、梯度和优化器状态。
为了解决这个问题,NLP 社区开发了参数高效的微调方法,可以保持大部分预训练模型的完整性。其中一些选择了现有参数的子集,其他人用额外的可训练权重来增强模型。
尽管内存要求较低,但参数高效的方法通常与完整模型微调具有竞争力。甚至在低数据情况下表现优良。对于我们的用例来说,这些方法的另一个吸引人的特性是它们允许在不同用途之间快速切换预训练的 LLM。
Distributed fine-tuning. 分布式微调
分布式网络中微调的核心原则是客户端“拥有”经过训练的参数,而服务器托管原始的预训练层。 服务器可以通过其层运行反向传播并返回与激活相关的梯度,但它们不会更新服务器端参数。因此,客户端可以在同一组服务器上同时运行不同的训练任务,而不会相互干扰。
为了说明这一原理,我们首先回顾一个用于文本分类的软提示调整的示例,然后将其推广到其他方法和任务。与第 2.1 节类似,客户端在本地存储嵌入层并依赖服务器来计算 Transformer 块的激活。在这种微调场景中,客户端需要存储可训练的软提示(特定于任务的输入嵌入)和线性分类头。
对于每个训练批次,客户端通过远程服务器链路由其数据以计算句子表示,然后使用分类器头获得预测并计算交叉熵损失。在反向传播期间,客户端以相反的顺序通过同一服务器链运行其数据,以计算学习到的提示向量的梯度。获得这些梯度后,客户端可以使用常规 PyTorch 优化器来更新头部和提示的参数,然后继续进行下一个小批量。
User interface. 用户界面
为了让用户在训练工作负载中具有更大的灵活性,我们使分布式反向传播模块与 PyTorch Autograd 引擎兼容。与推理阶段一样,该模块对用户透明地处理容错和负载平衡,同时允许他们访问中间激活并插入自定义 PyTorch 模块。图 4 显示了示例训练代码片段。
该接口还可以支持其他流行的参数高效微调算法,例如 LoRA 或 prefix tuning。最后,用户可以在一些现有块之后插入自定义本地模块,这可以允许诸如检索增强生成的用例。
# Initialize distributed BLOOM with soft prompts
model = AutoModelForPromptTuning.from_pretrained( "bigscience/distributed-bloom")
# Define optimizer for prompts and linear head
optimizer = torch.optim.AdamW(model.parameters())
for input_ids, labels in data_loader:
# Forward pass with local and remote layers
outputs = model.forward(input_ids)
loss = cross_entropy(outputs.logits, labels)
# Distributed backward w.r.t. local params
loss.backward() # Compute model.prompts.grad
optimizer.step() # Update local params only
optimizer.zero_grad()
2.3 Sharing and reusing trained modules 共享和重用训练好的模块
尽管预训练模型的大多数微调扩展可以轻松按原样共享,但简化共享这些扩展的工作流程使用户能够更轻松地使模型适应其目标场景。事实上,现有的model hubs, TensorFlow Hub; PyTorch Hub 由于支持许多模型且易于使用而获得了极大的欢迎,特别是在针对给定问题审查不同的预训练模型时。一个特别相关的项目是 AdapterHub,一个经过训练的适配器的存储库,以及一个实现不同适应方法的库。虽然 Petals 不依赖于 AdapterHub,但可以利用该库在分布式设置中训练适配器。相反,我们支持共享用户通过 Hugging Face Hub(也被 AdapterHub 用作后端)训练的模块。其基础设施和相应的开源库简化了已经熟悉该生态系统的用户的学习过程。由于 Hugging Face Hub 上的主要导航机制是已应用于上传模块的标签,因此用户只需要接受训练的任务以及构建适配器的模型。上传权重和微调模块的代码是通过将它们提交到 Git 存储库来完成的。浏览 Hub 时,用户可以通过按所需标签过滤所有可用模块的列表来选择最合适的适配器。
3 Internal structure and optimizations 内部结构及优化
分布式推理的主要考虑因素之一是其性能。它可以分为三个主要方面:计算速度(5年历史的游戏GPU与新数据中心GPU)、由于节点之间的距离而导致的通信延迟(洲际与本地)以及由于带宽而导致的通信延迟(10 Mbit/s 与 10 Gbit/s)。
就原始 FLOP 而言,即使是像 GeForce RTX 3070 这样的消费级 GPU 也可以在不到一秒的时间内运行 BLOOM-176B 的完整推理步骤 NVIDIA (2020)。然而,GPU 内存只能容纳一小部分模型层:简单地运行需要 44 个 RTX 3070 GPU 和 44 轮通信。为了提高效率,我们使用量化来为每个 GPU 存储更多参数,从而减少连续设备和通信轮次的数量(第 3.1 节)。最重要的是,每个客户端都会优先考虑附近的服务器,以使通信轮次更快(第 3.2 节)。
3.1 Large model inference on consumer GPUs 消费级GPU上的大型模型推理
我们假设每台服务器至少有 16 GB CPU RAM、8 GB GPU 内存。从这个假设来看,主要考虑因素之一是减少模型内存占用,以便每个设备可以容纳更多的 Transformer 块。
例如,BLOOM 有 176B 个参数,在 16 位精度下需要 352 GB 的 GPU 内存。因此,在最坏的情况下,模型分布在 352 GB / 8 GB(每台服务器)= 44 个节点中。我们可以通过两种方式减少数据传输的频率和数量。首先,我们可以通过压缩节点之间交换的隐藏状态来实现这一点。其次,我们可以将权重压缩到 8 位精度,从而减少保存所有层所需的节点数量。对于 BLOOM,这会将所需节点的数量从 44 个更改为 22 个,从而将延迟减少一半并降低故障概率。
Compressing communication buffers. 压缩通信缓冲区
为了在后续管道阶段之间发送更少的数据,我们使用动态分块量化。我们将其应用于管道并行通信之前的隐藏状态,如 Ryabinin 等人所做的那样。动态分块量化将带宽需求减半,并且对生成质量没有任何明显影响。
Compressing model weights. 压缩模型权重
正如 Dettmers 等人所建议的,我们使用 8 位混合矩阵分解进行矩阵乘法,将权重量化为 8 位精度,并与 16 位权重相比减少内存占用。 这种分解将隐藏状态和权重分成两部分:约 0.1% 的 16 位异常值和 99.9% 的 8 位常规值,这大约使内存占用量减半。

表 1:具有 8 位和 16 位权重的 OPT-175B 和 BLOOM-176B 的零射击精度。
如表 1 所示,该方法对主要基准测试的 LLM 质量影响很小。就推理时间而言,表 2 表明,批量大小为 1(20 个令牌)时,量化的开销约为 5%,但对于较大的批量,可以忽略不计。
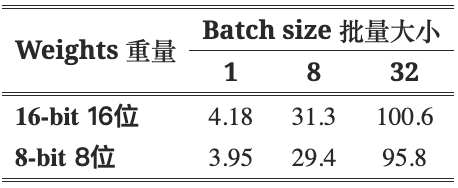
表 2:BLOOM-176B 在 8 个具有 8 位和 16 位权重的 A100 GPU 上的生成吞吐量(令牌/秒)
3.2 Collaborating over the Internet 通过互联网进行协作
另一个重要的挑战是在节点随时加入、离开或失败的情况下提供可靠的推理和训练。为了解决这个问题,Petals 使用 hivemind 库为服务器和客户端进行去中心化培训和自定义容错协议。
Server load balancing. 服务器负载平衡
首先,我们确保服务器在 Transformer 块之间均匀分布。形式上,服务器通过选择吞吐量最差的块并消除潜在的瓶颈来最大化总模型吞吐量。
每个服务器定期向分布式哈希表宣布其活动块。当新服务器加入时,它使用此信息来识别包含大多数具有最差吞吐量的块的块间隔。该间隔始终是连续的,因为分割它会损害推理延迟。一旦服务器选择了其层,它就会测量自己的吞吐量(网络和计算)并将其公布到分布式哈希表。
由于对等点可能随时离开或失败,因此所有节点都会定期检查启动重新平衡过程是否会显着提高整体吞吐量。如果是这种情况,它们会切换层,直到吞吐量变得接近最佳。特别是,如果服务某些块的所有对等点突然离开系统,此过程会快速重新分配剩余资源以弥补出现的差距。
Client-side routing. 客户端路由
接下来,我们希望客户端能够找到在最短的时间内运行模型的服务器序列。 在生成过程中,客户端一次处理一个或几个代币;在实践中,推理时间主要对网络延迟敏感。因此,客户端必须 ping 附近的服务器来测量延迟,然后通过波束搜索以最短的时间找到路径。 相反,在微调过程中,需要并行处理一批示例。在这里,客户可以使用 Ryabinin 等人的算法在多个服务器之间拆分批次。 (2021)。如果服务器在训练或推理期间发生故障,客户端会将其从考虑中删除并重新运行路由以查找替代服务器。在推理过程中,客户端将所有先前的输入发送到替换服务器,以便它具有相同的注意键和值。
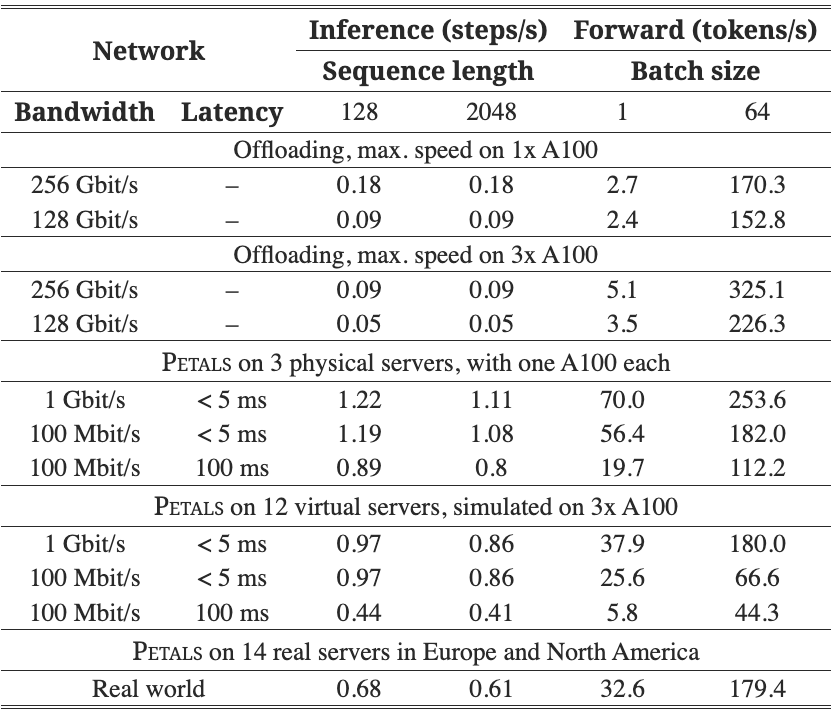
表 3:顺序推理步骤和训练时间前向传递的性能。
3.3 Benchmarks 基准测试
我们通过在模拟和真实设置中运行 BLOOM-176B 来评估 Petals 的性能。我们的第一个设置由 3 台本地服务器组成,每台服务器都在 A100 80GB GPU 上运行。这是一个乐观的场景,需要最少的沟通。在第二个设置中,我们通过将每个 A100-80GB 划分为多个虚拟服务器(3 个大服务器和 1 个小服务器)来模拟 12 个较弱的设备。我们使用三种网络配置评估上述设置:1 Gbit/s,延迟 < 5 ms,100 Mbit/s,延迟 < 5 ms,以及 100 Mbit/s,延迟 100 ms 2 。客户端节点有 8 个 CPU 核心,没有 GPU。
接下来,我们在现实世界的分布式环境中对 BLOOM 进行基准测试,其中包含 14 台较小的服务器,其中包含 RTX 2×3060、4×2080Ti、2×3090、2×A4000 和 4×A5000 GPU。这些是个人服务器和来自大学实验室的服务器,分布在欧洲和北美,并以 100-1000 Mbit/s 的速度连接到互联网。其中四台服务器在防火墙下运行。
在表 3 中,我们报告了顺序推理和训练时间前向传递的性能。对于推理而言,性能不太依赖于带宽或序列长度,但在高延迟设置中会降低,尤其是对于 12 个虚拟服务器。反过来,大批量的训练时间前向传播会受到带宽和延迟的影响。
我们还测试了拥有多个客户端的效果。对于 12 台具有 100 Mbit/s 带宽和 100 ms 延迟的服务器,如果 8 个客户端同时运行推理,则与单独运行推理的情况相比,每个客户端都会 ≈20% 减慢。
此外,我们将 Petals 与参数卸载进行比较,以在资源有限的情况下运行大型模型(Ren 等人,2021;Rajbhandari 等人,2021)。对于卸载基准,我们计算最大推理和前向训练吞吐量,以获得卸载性能的上限。我们的卸载数据基于最佳的卸载硬件设置:通过 PCIe 4.0 进行 CPU RAM 卸载,每个 GPU 具有 16 个 PCIe 通道,以及用于 GPU 对的 PCIe 交换机。
我们计算卸载的最大吞吐量如下。在 8 位中,该模型每十亿个参数使用 1 GB 内存,而具有 16 通道的 PCIe 4.0 的吞吐量为 256 Gbit/s(如果 PCIe 交换机后面有两个 GPU,则吞吐量为 128 Gbit/s)。因此,卸载 176B 参数对于常规设置需要 5.5 秒,对于多 GPU 设置需要 11 秒。我们假设上限估计的卸载延迟为零。
这些结果也显示在表 3 中。我们可以看到,与 Petals 相比,卸载的推理速度慢了大约一个数量级。对于训练时间前向传递,如果使用多个 GPU 并且 Petals 的网络限制为 100 Mbit/s 或具有高延迟,则卸载具有竞争力。在其他情况下,Petals 提供比训练卸载更高的吞吐量。
4 Discussion and future work
Incentives for peers to contribute. 激励同行做出贡献
在 Petals 中,使用客户端的节点不需要运行服务器。当然,这可能会导致网络中供应(专用 GPU 来服务模型层的节点)和需求(使用服务器根据自己的需求执行推理或微调的节点)之间的不平衡。鼓励用户为模型层提供服务的一种方法是引入激励系统:运行服务器的节点将获得特殊积分,这些积分可以用于高优先级的推理和微调或交换其他奖励。 我们在这次演示中没有包含这样的激励系统,以使其专注于技术方面;然而,一旦活跃用户群发展起来,它就可以被开发和部署。
Security. 安全
我们假设系统中的服务器由许多独立方运行。在实践中,其中一些可能会出现错误并返回错误的输出,而不是前向和后向传递的实际结果。发生这种情况的原因可能是恶意影响其他人的输出,或者在引入奖励时(如上所述),在不实际执行计算的情况下为服务层获得奖励。
解决这些问题的一种可能方法是使用经济驱动的方法。一些服务器可以通过存入一定数量的积分作为质押来保证其输出的正确性(例如,以换取增加的推理价格)。然后,对于每个请求,他们都会公布输入和输出张量的加密哈希,因此拥有输入的任何人都可以检查输出是否正确。
如果有人发现由可信第三方确认的不匹配,他们可以索取服务器的承诺作为奖励。在实践中,可能是客户怀疑自己收到了错误的输出,也可能是“赏金猎人”向不同的服务器发送请求以希望捕获错误。虽然这种方法仍然有可能收到错误的输出,但它使作弊成本高昂,并激励人们快速暴露恶意服务器。
Privacy. 隐私
我们方法的一个关键限制是,服务于模型第一层的节点可以使用他们的输入来恢复输入令牌。因此,处理敏感数据的客户应仅使用由允许处理此数据的受信任机构托管的服务器。 这一限制可能会在未来使用安全多方计算 Evans 等人的工作中得到解决。 (2018)或隐私保护硬件 NVIDIA(2022)。
Making changes to the main model. 对主模型进行更改
正如 2.2 节中所讨论的,分布式参数高效微调使用户可以轻松地将基本模型应用于新任务。在第 2.3 节中,我们还描述了如何让其他人轻松共享和重用这些更新。此功能为机器学习模型的协作改进迈出了有意义的一步:随着越来越多的用户训练基础模型,随着时间的推移,它将有效地变得更加强大。
此外,我们可能期望在特定任务上表现最佳的模型参数会随着时间的推移而变化。与代码的版本控制系统类似,跟踪微调模型参数的版本变化非常有用。一种用于在“实时基准”上快速测试一组参数性能的系统对于确保后续版本提高所需功能非常有价值。
除了适应新任务之外,最终更新主模型也很有用。理想情况下,可以以有原则的方式跟踪此类更新。 Petals 的用户可以指定他们想要使用的模型版本,服务器可以指示他们支持哪些版本。然后引入模型的新版本减少为添加一组新的层,然后根据 3.2 节中的方法自然地取代旧的参数。类似地,微调的模型适配器可以用表示它们适用的模型版本的标签进行注释。这种细粒度的模型版本控制目前并不常见,但可以直接添加到 Petals 中。
5 Conclusion 结论
本文介绍了 Petals,一个用于大型语言模型的高效协作推理和微调的系统。我们提供用户友好的生成界面和灵活的 API 来访问通过互联网提供的模型。我们使用 8 位压缩来减少运行大型模型的资源需求。此外,我们还开发了可靠路由和负载平衡的算法。
由于 Petals 是开源的,我们希望它能够根据社区的反馈不断发展,融入相关的研究进展并增加对所需功能的支持。随着该系统的发布,我们希望扩大对大型语言模型的访问,并为以前不可能或过于昂贵的应用、研究或研究问题铺平道路。
Acknowledgements 致谢
作者衷心感谢 Cheng-Xin Yong、Ilya Dimov、Yozh、Teven Le Scao、Stas Bekman 和 Haokun Liu 的有益讨论。我们还要感谢 Teven Le Scao 在设计图 1 时提供的帮助。部分实验是在 Elena Voita 的个人服务器上进行的。